추가, 수정 API 보다도 조회 API가 성능에 가장 민감한 만큼 JPA를 사용할 때 조회 API의 성능을 최적화하는 방법을 단계별로 정리하려 합니다. 주문과 배송정보 그리고 회원을 조회하는 API를 만들고 지연 로딩에 의해 발생하는 성능 문제를 해결해보려 합니다. 이번 글에서는 ManyToOne, OneToOne 과 같은 xToOne 관계를 조회하는 경우를 살펴보겠습니다.
아래 그림과 같이 주문, 배송정보, 회원은 모두 엔티티로 존재하고 주문과 회원이 다대일 양방향 연관관계 그리고 주문과 배송정보가 일대일 양방향 연관관계로 되어 있습니다.

주문 조회 V1: 엔티티를 직접 노출
@RestController
@RequiredArgsConstructor
public class OrderSimpleApiController {
private final OrderRepository orderRepository;
/**
* V1. 엔티티 직접 노출
* - Hibernate5Module 모듈 등록, LAZY = null 처리
* - 양방향 관계 문제 발생 -> @JsonIgnore
*/
@GetMapping("/api/v1/simple-orders")
public List<Order> ordersV1() {
List<Order> all = orderRespitory.findAllByString(new OrderSearch());
for (Order order: all) {
order.getMember().getName();
order.getDelievery().getAddress();
}
return all;
}
}
엔티티를 API 스펙에 그대로 노출했을 때 어떤 문제가 있을까요?
기본적으로 엔티티가 API 스펙에 노출되면 엔티티의 변경이 곧바로 API 스펙 변경으로 이어지는 문제가 발생합니다.
그리고 @Valid와 같은 프레젠테이션 계층에 어울리는 처리 로직이 엔티티에 들어가는 문제도 발생합니다. @Valid 조건의 종류는 각각의 API 마다 달라질 수 있는데 DTO가 아닌 엔티티를 스펙에 드대로 노출하면 이를 대응할 수 없게 됩니다.
심지어 조회하려는 엔티티에 양방향 연관관계로 묶인 다른 엔티티가 있다면 jackson 라이브러리가 객체를 json으로 생성할 때 무한루프를 도는 문제도 발생합니다. 예를 들어 Member와 Order가 양방향으로 걸려 있다면 jackson 라이브러리가 엔티티 자체를 json 객체로 생성하기 위해 Order -> Member -> Order -> Member...로 무한루프에 빠집니다.
이때는 양방향 연관관계 엔티티 중 하나를 @JsonIgnore 처리해야 합니다. 하지만 양방향 연관관계 엔티티 중 하나를 @JsonIgnore 처리하여 무한루프를 피할 수 있었지만 아래와 같은 또 다른 에러를 마주하게 됩니다.
InvalidDefinitionException: No serializer found for class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor and no properties discovered to create BeanSerializer
에러를 살펴보면 hibernate... bytebuddy... 등등이 나오는데. 이 에러는 JPA 엔티티의 지연 로딩(LAZY) 설정으로 프록시 객체를 jackson 라이브러리가 json 객체로 생성하려 하려고 할 때 발생하는 에러입니다. JPA를 사용한다면 엔티티끼리의 관계에서 항상 EAGER가 아닌 LAZY로 설정할 것입니다.
이때 LAZY로 설정된 경우 실제로 해당 프로퍼티에 접근하기 전까지 실제 DB에서 조회한 객체가 아닌 프록시 객체가 해당 프로퍼티를 채우고 있습니다. 만약 LAZY로 설정된 프로퍼티에 실제로 접근하면 그때 DB에 조회 쿼리를 날려 실제 객체로 채우는 방식입니다. 지연 로딩은 엔티티를 조회할 때 그 엔티티와 연관관계로 묶여있는 모든 엔티티를 조회하게 되면 말도 안 되게 많은 불필요하고 예측 불가능한 조회 쿼리를 방지하기 위한 설정입니다. 하지만 이렇게 지연 로딩을 걸어두면 jackson 라이브러리가 for에서 Order 리스트를 루프를 돌며 Member에 접근했을 때 순수 Java 객체가 아닌 프록시 객체를 만나며 에러를 발생하게 되는 것입니다. 위의 에러에서 나오는 bytebuddy가 hibernate에서 엔티티 프록시로 사용하는 객체입니다.
사실 위 에러는 엔티티를 API 스펙에 노출하지 않았다면, jackson 라이브러리가 프록시 객체를 Json으로 생성할 일도 없기 때문에 발생할 일 없는 에러입니다. 그렇지만 해결 방법은 알고 있으면 좋겠죠?
위 에러를 해결하기 위해서는 지연 로딩으로 설정된 연관관계 엔티티의 경우에는 jackson 라이브러리에게 이 프록시 객체를 json으로 뿌리지 않도록 설정해야 합니다. 이를 위해서는 스프링 부트 3.0 미만의 경우 Hibernate5Module을 스프링 빈으로 등록하고 스프링 부트 3.0 이상이라며 Hibernate5JakartaModule을 등록해야 합니다.
아래 코드와 같이 build.gradle에 라이브러리를 추가하고 스프링 빈으로 등록하면 됩니다.
// build.gradle
implementation 'com.fasterxml.jackson.datatype:jackson-datatype-hibernate5-jakarta'
// application class
@Bean
Hibernate5JakartaModule hibernate5Module() {
return new Hibernate5JakartaModule();
}
하지만 엔티티에 API 스펙을 노출하지 않도록 만든다면 이런 귀찮은 설정도 필요 없게 됩니다. 그리고 지연 로딩에 의한 문제라고 해서 절대로 즉시 로딩(EAGER)을 사용해서는 안됩니다. 즉시 로딩으로 설정하면 성능 튜닝이 매우 어려워집니다.
항상 지연 로딩(LAZY)을 기본으로 하고, 성능 최적화가 필요한 경우에는 페치 조인(fetch join)을 사용합시다. 페치 조인에 대해서는 아래에서 살펴보겠습니다.
주문 조회 V2: 엔티티를 DTO로 변환
@Data
static class SimpleOrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderstatus = order.getStatus();
address = order.getDelievery().getAddress();
}
}
/**
* V2. 엔티티를 조회해서 DTO로 변환 (fetch join 사용X)
* - 단점: 지연로딩으로 쿼리 N번 호출
*/
@GetMapping("/api/v2/simple-orders")
public List<SimpleOrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<SimpleOrderDto> result = orders.stream()
.map(o -> new SimpleOrderDto(o))
.collect(toList());
return result
}
V2는 엔티티를 DTO로 변환하는 일반적인 방법입니다.
V1과 달리 V2에서는 엔티티를 API 스펙에 노출하지 않고 엔티티를 DTO(Data Transfer Object)로 변환하여 리턴했습니다.
V1에서 API 스펙에 엔티티를 노출하며 생기던 문제는 발생하지 않지만, 엔티티 지연 로딩에 의해 N+1 문제가 발생하여
성능에 문제가 생길 수 있습니다.
지연 로딩에 의한 N+1 문제는 order 엔티티 조회 1번에 order와 연관관계를 가진 member와 delivery 엔티티를 SimpleOrderDto가 필요로 하기 때문에 프록시 객체로 대체되었던 member와 delivery 값을 DB에 조회하는 쿼리를 보내며 발생합니다.
프록시 객체를 실제 DB에서 가져온 값으로 대체하기 위해서 order 조회 1번에 order -> member 지연 로딩 조회 N번 그리고 order -> delivery 지연 로딩 조회 N번으로 총 1 + N + N번 쿼리가 실행됩니다.
예를 들어 order를 조회했을 때 4개가 조회되었다면 최악의 경우 1 + 4 + 4의 쿼리가 실행됩니다. 물론 지연 로딩은 DB에 SELECT 쿼리를 날리기 전에 영속성 컨텍스트에 먼저 조회하는데 이때 영속성 컨텍스트에 저장되어 있다면 DB에 SELECT 쿼리를 날리지 않습니다. 하지만 항상 최악의 경우를 고려해야 하기 때문에 영속성 컨텍스트의 캐싱이 큰 의미를 가지진 않습니다.
V2에서 엔티티의 지연 로딩에 의해 1 + N 문제가 발생했다고 해서 지연 로딩을 즉시 로딩(EAGER)으로 바꿔 문제를 해결하려 하면 절대로 안됩니다. 즉시 로딩은 1 + N 문제보다 더 큰 문제를 발생시킬 수 있습니다.
V2의 1 + N 문제를 페치 조인으로 V3에서 해결해 보겠습니다.
주문 조회 V3: 엔티티를 DTO로 변환 - 페치 조인 최적화
/**
* V3. 엔티티를 조회해서 DTO로 변환 (fetch join 사용O)
* - fetch join으로 쿼리 1번 호출
*/
// OrderSimpleApiController 코드
@GetMapping("/api/v3/simple-orders")
public List<SimpleOrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithMemberDelivery();
List<SimpleOrderDto> result = orders.stream()
.map(o -> new SimpleOrderDro(o))
.collect(toList());
return result;
}
// OrderRepository 코드
public List<Order> findAllWithMemberDelivery() {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class)
.getResultList();
)
}
V3에서는 엔티티를 페치 조인(fetch join)을 사용해서 쿼리 1번에 조회하여 성능을 개선했습니다. 페치 조인을 사용해서 order 엔티티 조회 시 memeber와 delivery를 한 번에 다 가져옵니다. 페치 조인으로 조회할 때는 지연 로딩으로 설정한 엔티티라도 무시하고 프록시가 아닌 실제 값을 채우게 됩니다.
페치 조인으로 order -> member, order -> delivery는 이미 조회된 상태이므로 지연 로딩에 의해 프록시 객체가 들어가지 않으며 추가적인 SELECT 쿼리도 나가지 않습니다. 페치 조인을 사용해 최악의 경우 1 + 2N 번 나가던 쿼리문을 1번으로 줄였습니다.
하지만 V3와 같이 페치 조인을 사용할 경우 한 번에 값들의 가져오기 때문에 아래와 같이 1번의 SELECT 쿼리의 필드 수가 커진다는 단점이 존재합니다.
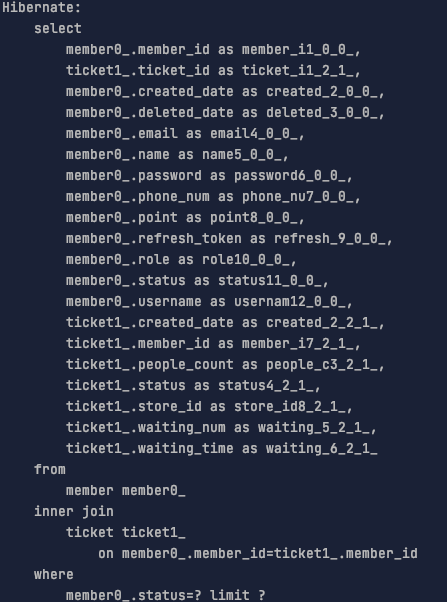
사실 쿼리의 SELECT 필드 수가 성능에 큰 영향을 미치진 않습니다. SELECT 필드 수보다 join이나 where문에서 성능이 많이 좌우됩니다. 하지만 SELECT 필드 수가 너무 커지면 이를 최적화하는 방법도 존재합니다. V4를 통해 소개하겠습니다.
주문 조회 V4: JPA에서 DTO로 바로 조회
public class OrderSimpleApiController {
...
private final OrderSimpleQueryRepository orderSimpleQueryRepository;
/**
* V4. JPA에서 DTO로 바로 조회
* - 쿼리 1번 호출
* - select 절에서 원하는 데이터만 선택해서 조회
*/
@GetMapping("/api/v4/simple-orders")
public List<OrderSimpleQueryDto> ordersV4() {
return orderSimpleQueryRepository.findOrderDtos();
}
}
@Repository
@RequiredArgsConstructor
public class OrderSimpleQueryRepository {
private final EntityManager em;
public List<OrderSimpleQueryDto> findOrderDtos() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.simplequery.OrderSimpleQueryDto(o.id, m.name, o.orderDate, o.status, d.address)" +
" from Order o" +
" join o.member m" +
" join o.delivery d", OrderSimpleQueryDto.class)
.getResultList();
)
}
}
@Data
public class OrderSimpleQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public OrderSimpleQueryDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatuts;
this.address = address;
}
}
V4 방식은 JPA에서 DTO로 바로 조회하는 방식으로 일반적인 SQL을 사용할 때처럼 원하는 값을 선택해서 조회합니다.createQuery에서 new 명령어를 사용해서 JPQL의 결과를 DTO로 즉시 변환합니다. 이때 new로 생성하는 객체의 생성자에는 엔티티를 넘길 수 없습니다. new로 생성하는 객체의 생성자에서 넘어오는 정보를 식별자로 인식하기 때문에 엔티티를 넘기지 못하고 값을 일일이 넘겨야 합니다.
V3처럼 엔티티를 조회하고 DTO로 변환하지 않고, V4처럼 DTO로 바로 조회할 경우 클라이언트에 전달할 DTO에 필요한 정보만 뽑아서 SELECT 할 수 있기 때문에 한 번 나가는 쿼리의 SELECT 부분을 줄일 수 있습니다. SELECT 절에서 원하는 데이터를 직접 선택하여 애플리케이션 네트워크 용량을 최적화했지만 이는 생각보다 미비한 수준입니다.
그리고 findOrdersDtos 메서드를 기존에 사용하던 Repository 클래스에 두지 않고 별도의 클래스(OrderSimpleQueryRespoitory)를 만들어서 따로 분리했습니다. Repository 계층은 엔티티의 객체 그래프를 조회하는 역할을 합니다. V3의 fetch join 방식까지는 단순 엔티티 조회였기 때문에 Repository 계층에 어울렸지만, V4 방식은 순수한 Repository 계층의 역할과는 어울리지 않습니다.V4 방식은 엔티티가 아니라 DTO에 의존하기 때문에 findOrderDtos 메서드는 한정된 DTO에만 어울리게 됩니다. 조회 전용으로 API 스펙(DTO)에 맞춰서 사용하는 느낌이 강하기 때문에 findOrdersDtos 메서드를 별도의 클래스로 분리했습니다. 이렇게 성능최적화 쿼리용 패키지를 뽑아서 별도의 클래스로 관리하는 경우가 많습니다.
하지만 V4 방식은 Repository를 분리했다고 하더라도 DTO에 맞춰진 코드로 재사용성이 떨어지고, API 스펙에 맞춘 코드가 Repository에 들어간다는 단점이 존재합니다.
V3 vs V4
엔티티를 DTO로 반환하거나, DTO로 바로 조회하는 방식은 각각 장단점이 있습니다. V3 방식은 엔티티 자체를 조회하기 때문에 여러 API에서 여러 형태의 DTO로 변환이 가능합니다. 또한 엔티티를 가져와서 비즈니스 로직에서 데이터를 변경하여 변경 감지의 기능도 사용 가능합니다.V4 방식은 정해진 하나의 DTO에만 적용되기 때문에 재사용성 측면에서 불리하지만 성능은 V3 방식보다 좋습니다. DTO로 조회하기 때문에 엔티티의 변경 감지 기능은 사용할 수 없습니다.V3와 V4 방식 중 상황에 따라서 더 나은 방법을 선택하도록 합시다. 쿼리 방식 선택에 권장하는 순서는 아래와 같습니다.
- 우선 엔티티를 DTO로 변환하는 방법을 선택합니다. (V3)
- 필요하면 페치 조인으로 성능을 최적화합니다. 페치 조인으로 대부분의 성능 이슈가 해결됩니다. (V3)
- 그래도 안되면 DTO로 직접 조회하는 방법을 사용합니다. (V4)
- 최후의 방법은 JPA가 제공하는 네이티브 SQL이나 스프링 JDBC Template을 사용해서 SQL을 직접 사용합니다.
'Spring > API 성능 최적화' 카테고리의 다른 글
| 컬렉션 조회 API 성능 최적화 (V5. JPA에서 DTO 직접 조회) (0) | 2024.10.13 |
|---|---|
| OSIV와 성능 최적화 (0) | 2024.10.12 |
| 컬렉션 조회 API 성능 최적화 (V4. hibernate.default_batch_fetch_size) (0) | 2024.10.05 |
| 컬렉션 조회 API 성능 최적화 (V1 ~ V3. 컬렉션 페치 조인과 데이터 뻥튀기) (1) | 2024.10.01 |


